8.8 KiB
nanoGPT

The simplest, fastest repository for training/finetuning medium-sized GPTs. It is a rewrite of minGPT that prioritizes teeth over education. Still under active development, but currently the file train.py reproduces GPT-2 (124M) on OpenWebText, running on a single 8XA100 40GB node in 38 hours of training. The code itself is plain and readable: train.py is a ~300-line boilerplate training loop and model.py a ~300-line GPT model definition, which can optionally load the GPT-2 weights from OpenAI. That's it.
Because the code is so simple, it is very easy to hack to your needs, train new models from scratch, or finetune pretrained checkpoints (e.g. biggest one currently available as a starting point would be the GPT-2 1.3B model from OpenAI).
install
Dependencies:
- pytorch <3
- numpy <3
pip install transformersfor huggingface transformers <3 (to load GPT-2 checkpoints)pip install datasetsfor huggingface datasets <3 (if you want to download + preprocess OpenWebText)pip install tiktokenfor OpenAI's fast BPE code <3pip install wandbfor optional logging <3pip install tqdm
usage
To render a dataset we first tokenize some documents into one simple long 1D array of token indices. E.g. for OpenWebText run:
$ cd data/openwebtext
$ python prepare.py
To download and tokenize the OpenWebText dataset. This will create a train.bin and val.bin which holds the GPT2 BPE token ids in one sequence, stored as raw uint16 bytes. Then we're ready to kick off training. The training script currently by default tries to reproduce the smallest GPT-2 released by OpenAI, i.e. the 124M version of GPT-2. We can train as follows on a single device, though I encourage you to read the code and see all of the settings and paths up top in the file:
$ python train.py
To train using PyTorch Distributed Data Parallel (DDP) run the script with torchrun. For example to train on a node with 4 GPUs run:
$ torchrun --standalone --nproc_per_node=4 train.py
Once some checkpoints are written to the output directory (e.g. ./out by default), we can sample from the model:
$ python sample.py
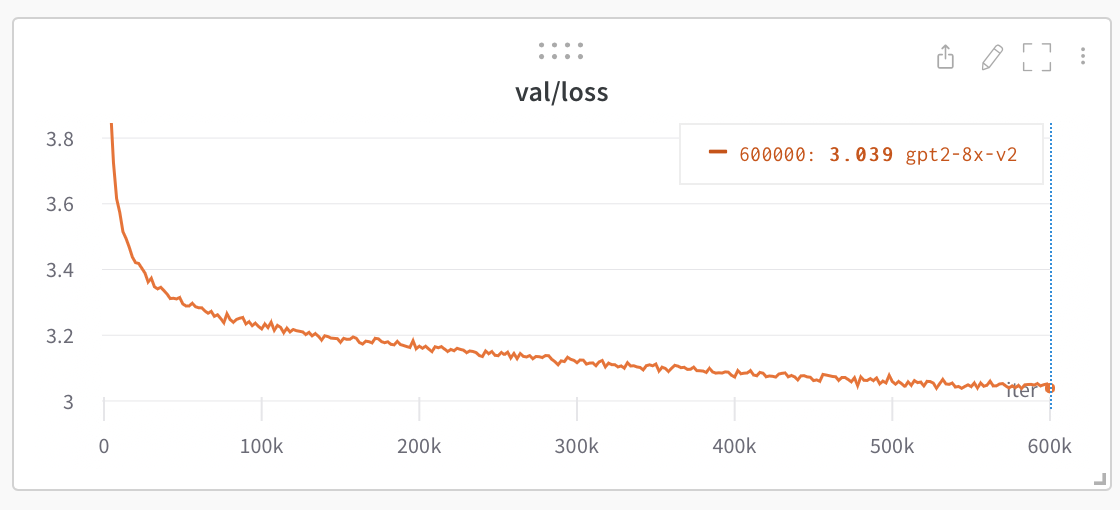
Training on 1 A100 40GB GPU overnight currently gets loss ~3.74, training on 4 gets ~3.60. Training on an 8 x A100 40GB node for ~500,000 iters (~1 day) atm gets down to ~3.1. Random chance at init is -ln(1/50257) = 10.82. Which brings us to baselines.
baselines
OpenAI GPT-2 checkpoints allow us to get some baselines in place for openwebtext. We can get the numbers as follows:
$ python train.py eval_gpt2
$ python train.py eval_gpt2_medium
$ python train.py eval_gpt2_large
$ python train.py eval_gpt2_xl
and observe the following losses on train and val:
| model | params | train loss | val loss |
|---|---|---|---|
| gpt2 | 124M | 3.11 | 3.12 |
| gpt2-medium | 350M | 2.85 | 2.84 |
| gpt2-large | 774M | 2.66 | 2.67 |
| gpt2-xl | 1558M | 2.56 | 2.54 |
I briefly tried finetuning gpt2 a bit more on our OWT and didn't notice dramatic improvements, suggesting that OWT is not much much different from WT in terms of the data distribution, but this needs a bit more thorough attempt once the code is in a better place.
finetuning
For an example of how to finetune a GPT on new text go to data/shakespeare and look at prepare.py to download the tiny shakespeare dataset and render it into a train.bin and val.bin. Unlike OpenWebText this will run in seconds. Finetuning takes very little time, e.g. on a single GPU just a few minutes. Run an example finetuning like:
$ python train.py config/finetune_shakespeare.py
This will load the config parameter overrides in config/finetune_shakespeare.py (I didn't tune them much though). Basically, we initialize from a GPT2 checkpoint with init_from and train as normal, except shorter and with a small learning rate. The best checkpoint (lowest validation loss) will be in the out_dir directory, e.g. in out-shakespeare by default, per the config file. You can then run the code in sample.py to generate infinite Shakespeare. Note that you'll have to edit it to point to the correct out_dir.
i only have a macbook
It's possible to play with the code if you only have a macbook or some other cheap computer. In this case it's much easier to just work with the Shakespeare dataset. Step 1 render the training data:
$ cd data/shakespeare
$ python prepare.py
Then launch the training script with a baby network, here is an example:
$ cd ../..
$ python train.py --dataset=shakespeare --n_layer=4 --n_head=4 --n_embd=64 --device=cpu --compile=False --eval_iters=1 --block_size=64 --batch_size=8
This creates a much smaller Transformer (4 layers, 4 heads, 64 embedding size), runs only on CPU, does not torch.compile the model (torch seems to give an error if you try), only evaluates for one iteration so you can see the training loop at work immediately, and also makes sure the context length is much smaller (e.g. 64 tokens), and the batch size is reduced to 8. On my MacBook Air (M1) this takes about 400ms per iteration. The network is still pretty expensive because the current vocabulary is hard-coded to be the GPT-2 BPE encodings of vocab_size=50257. So the embeddings table and the last layer are still massive.
You can now also work with tiny shakespeare on the character level, see data/shakespeare_char and run prepare.py to tokenize it on the character level. If you have a GPU you can use the decent starter settings in a provided config file, train as follows:
$ python train.py config/train_shakespeare_char.py
But if all you have is a CPU you may want to further override the settings down another notch, e.g.:
$ python train.py config/train_shakespeare_char.py --device=cpu --compile=False --eval_iters=20 --log_interval=1 --block_size=64 --batch_size=8
Where we decrease the context length to just 64 characters and only use a batch size of 8.
benchmarking
For model benchmarking bench.py might be useful. It's identical to what happens in the meat of the training loop of train.py, but omits much of the other complexities.
efficiency notes
Code by default now uses PyTorch 2.0. At the time of writing (Dec 29, 2022) this makes torch.compile() available in the nightly release. The improvement from the one line of code is noticeable, e.g. cutting down iteration time from ~250ms / iter to 135ms / iter. Nice work PyTorch team!
todos
A few todos I'm aware of:
Optimizations
- Additional optimizations to the running time
- Investigate need for an actual Data Loader with a dedicated worker process for data
- Look into more efficient fused optimizers (e.g. apex)
- Re-evaluate use of flash attention (previously I wasn't able to get the forward pass to match up so I took it out)
- CUDA Graphs?
- Investigate potential speedups from Lightning or huggingface Accelerate
Features / APIs
- Add back fp16 support? (would need to also add back gradient scaler)
- Finetune the finetuning script, I think the hyperparams are not great
- Report and track other metrics e.g. perplexity, num_tokens, MFU, ...
- Eval zero-shot perplexities on PTB, WikiText, other related benchmarks
Suspiciousness
- Current initialization (PyTorch default) departs from GPT-2. In a very quick experiment I found it to be superior to the one suggested in the papers, but that can't be right?
- I don't currently seem to need gradient clipping but it is very often used (?). Nothing is exploding so far at these scales but maybe I'm leaving performance on the table. Evaluate with/without.
- I am still not 100% confident that my GPT-2 small reproduction hyperparameters are good, if someone has reproduced GPT-2 I'd be eager to exchange notes ty
- I keep seeing different values cited for weight decay and AdamW betas, look into
- I can't exactly reproduce Chinchilla paper results, see scaling_laws.ipynb notebook
Results
- Actually reproduce GPT-2 results and have clean configs that reproduce the result. It was estimated ~3 years ago that the training cost of 1.5B model was ~$50K (?). Sounds a bit too high.
troubleshooting
- Note that by default this repo uses PyTorch 2.0 (i.e.
torch.compile). This is fairly new and experimental, and not yet available on all platforms (e.g. Windows). If you're running into related error messages try to disable this by adding--compile=Falseflag. This will slow down the code but at least it will run.
acknowledgements
All nanoGPT experiments are powered by GPUs on Lambda labs, the best Cloud GPU provider thank you :)